
VLMによる伝票処理アプリ
1.スキャンPDF画像のOCR課題
ローカル生成AIでVLM(Visual Language Model)が画像分類などで有効なことを報告しました。今回は一般的な事務作業での活用検討の報告です。以前、コードレスのAIフローを作成するDifyのデモプログラムを使って「名刺画像から氏名などの項目抽出」を試みましたが、ローカルモデルのllama3.2-visionでは日本語名刺読み取りは不得意で住所などが正確に読み取れませんでした。その反省を踏まえて日本語文字起こしに適したVLMの比較と選択を行いました。結果、漢字に強いVLM(qwen2.5vl)をが非常に良い仕事をしてくれました。電子化されてない事務書類はスキャンpdfファイルです。複数のスキャン画像を合体したもので、OCRを実施するためにはページごとに分解し各画像ごとに文字起しが必要です。まず、画像に分解するところからスタートしました。

伝票画像から、項目を抽出する方法を2つ考えました。①OCRを使用して、項目が記載されている領域から文字起こしする方法と②直接、画像をVLMに読み込ませ、抽出すべき項目の前後のテキストの情報などをプロンプトで与え、各項目値の抽出を行います。方法①は古典的AIで非力なPCでも動かせるメリットがあるので、まず方法①を検討しました。方法②は生成AI応用ですが、VLMの日本語解釈がうまくいかないと使えない可能性があります。

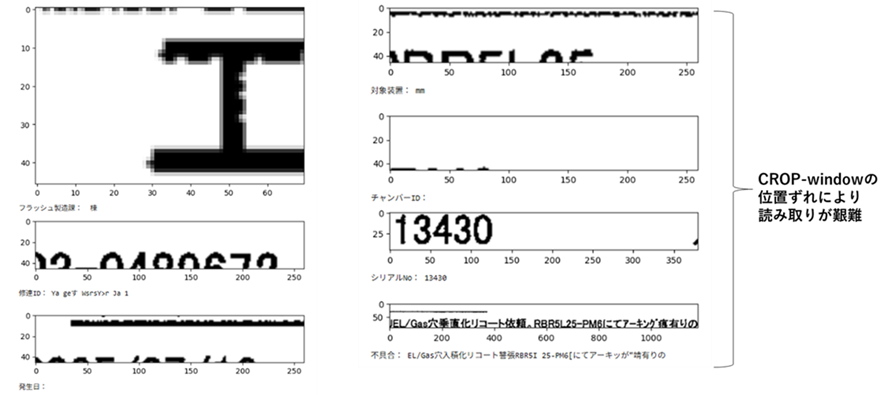
まず、方法①の検討を行いました。従来のOCRライブラリ(pytesseractなど)では、画像領域をクロップすることで必要項目を抽出することができます。問題は、スキャンした画像間で座標が微妙にずれていること、滲んでいたり欠損している場合もあります。特に不具合状況の記述欄は文字が小さく2段になる場合もあります。

最初の画像からは全8項目をうまく抽出できましたが、2枚目以降はスキャナーハードウェアの位置精度影響で文字クロップする場所がずれているため、正しく読み出すことができませんでした。スキャンpdfは印刷したもの複数枚を機械式スキャナで連続して読み込み1つのpdfファイルにまとめる一見便利なものですが、文字質、文字の傾き、文字位置に再現性がなく従来のTesseractやEasyOCRでは対応できませんでした。
2.VLMによる項目値の抽出
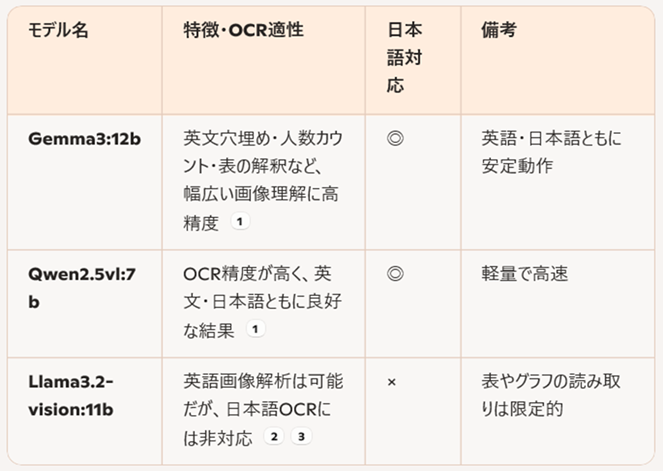
方法①:OCRを使用して、項目が記載されている領域から文字起こしする方法はうまくいきませんでした。方法②:直接、画像をVLMに読み込ませ、抽出すべき項目の前後のテキストの情報などをプロンプトで与え項目値を読み取る検討を行いました。Copilotの情報では、ollamaでOCR用途に適したVision-Language Model(VLM)候補は3つあるようです。gemma3:12bやllama3.2-visionは使用した経験がありましたが、新たにqwen2.5vl:7bを候補に挙げてくれました。
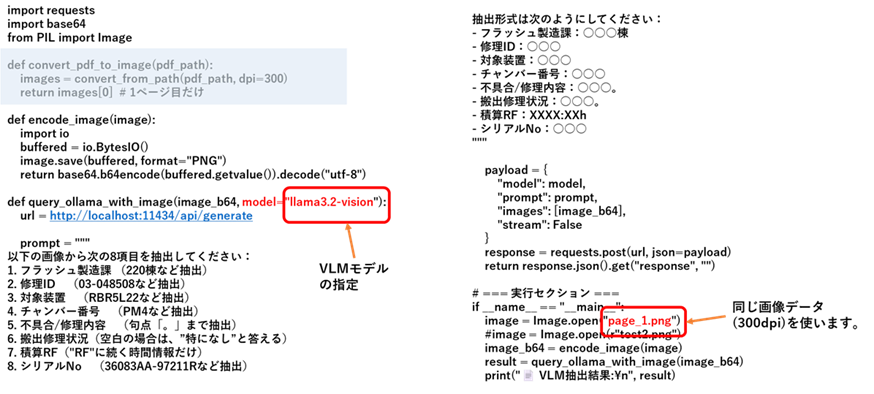
まず、画像から8項目を抽出するテストコードを示します。プロンプトには、抽出すべき項目とその例を与えました。また、出力形式は、項目と項目値を「:」で区切って出力するように指定しています。
使用したVLMモデルは、「llama3.2-vision」「gemma3:12b」「qwen2.5vl」の3種類です。回答を比較してみました。llama3.2-visionは日本語のテキストが返ってきませんでした(日本語抽出は苦手)。gemma3:12bはすべての項目について回答していますが判読できなかった項目値はプロンプトで与えた例を返してきました(嘘つきですね)。qwen2.5vl:7bは完全に予想外に素晴らしい回答が返ってきました。やはり、漢字の国である中国製は素晴らしいです。全問正解でした。
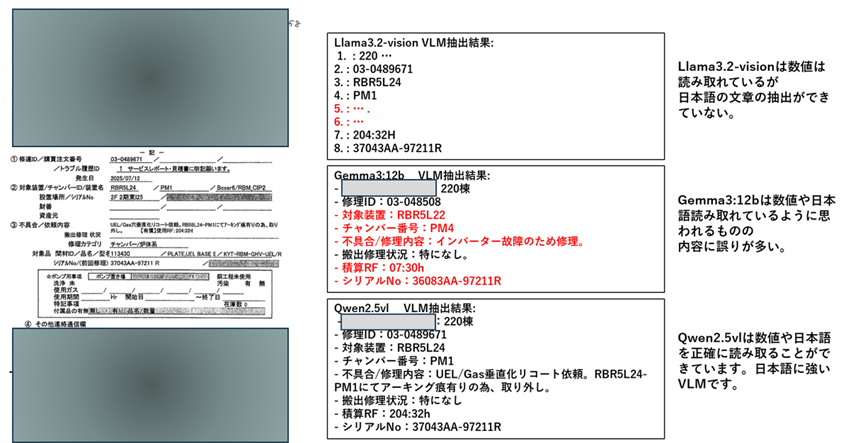
qwen2.5vl:7bが良い仕事をしてくれそうなので、方法②によるシステムアプリを構築してみようと思いました。入力はスキャンpdfです。画像に分解してVLMに入力します。前処理アプリ「pdf2png.exe」を経由して本体アプリ「VLM_GUI4.exe」につなぎ、ページごとの項目値抽出します。
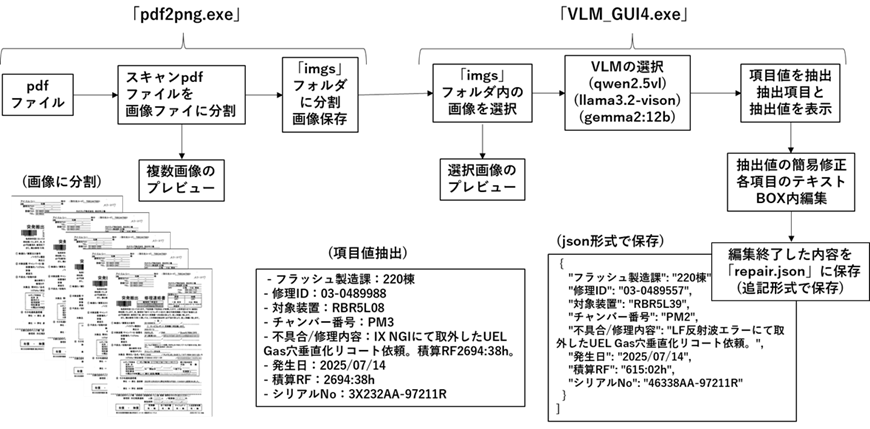
3.VLMによる項目抽出GUIアプリ開発
まず、VLMに送る前のpdfを画像に変換するGUIアプリについて説明します。pdfファイルをブラウズして読み込みます。画像に分割されると番号が付加されたファイル名で.png(300dpi)でimgsフォルダに保存されます。処理が終了すると、ファイルをクリアして次のpdfファイルを読み込むという操作を繰り返します。
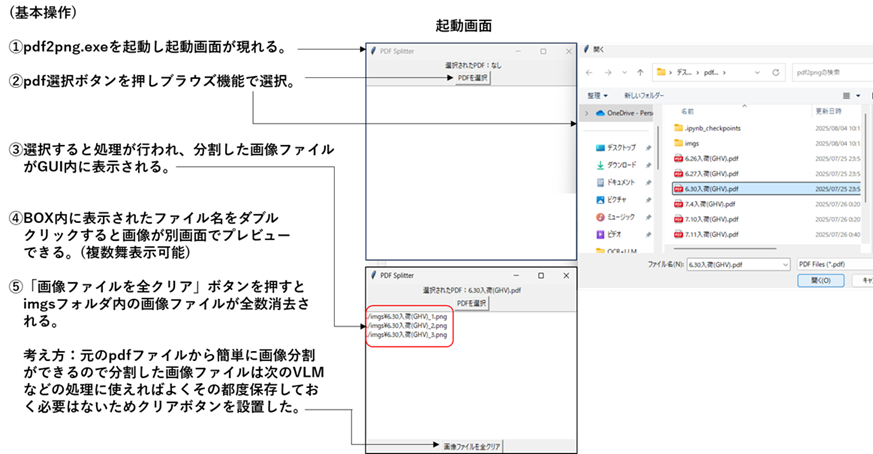
画像分割GUIアプリ「pdf2png.exe」のコードを示します。

VLMによる項目値抽出GUIアプリの画面を示します。起動するとimgsフォルダ内の画像ファイル一覧が表示されます。クリックして選び、プレビューを押すと画像が表示されます。(同時に複数枚表示できます)抽出ボタンを押すと、VLMが項目値を読み取り結果を8個のテキストBOXに表示します。テキストBOXは編集が可能で、プレビュー画像で確認しながら、誤っている部分を修正することができます。確認が終わったら保存ボタンを押すと「repair.json」ファイルに追記されます。
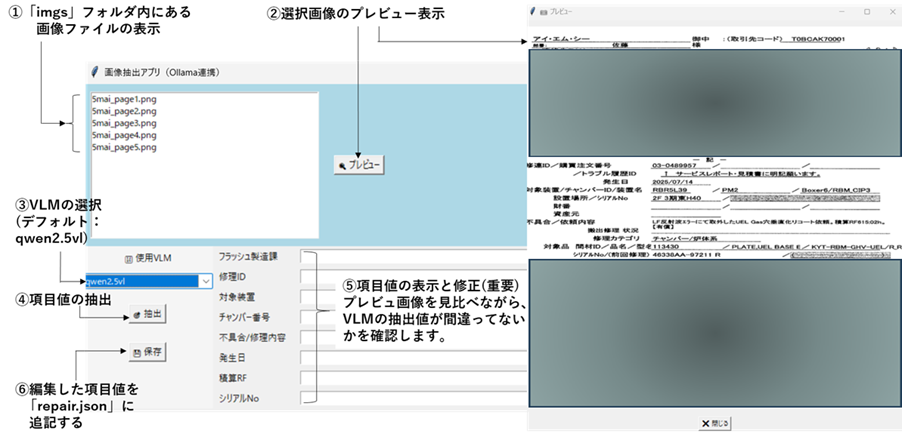
「VLM_GUI4.exe」のプログラムコードを示します。

コードの続きを示します。
4.SQLite3によるDB化とクエリ検索試験
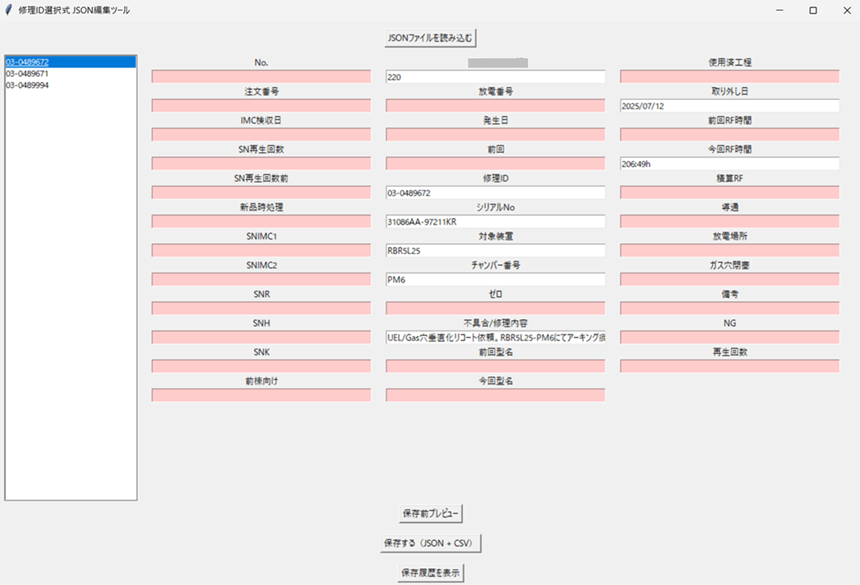
前回は伝票の項目を抽出し、jsonファイルに蓄積するところまでの説明でしたが、実際には過去データと連結し、例えばパーツS/Nから修理履歴を検索するようなシステムが必要だと思います。将来的にはSQLなどのリレーショナルデータベースで管理することで、LLMからのクエリ操作性が上がることも期待できます。まず、過去のマスターcsvと追加データを接続するGUIアプリを製作しました。詳細説明は割愛しますが、35項目中の8項目はVLMにより抽出したものです。起動すると「repair.json」を読み込み項目値を読み取ったデータの修理IDが表示されます。クリックするとそのIDの8項目のデータがマスター35項目の入力BOXに表示されます。入力BOXの赤い部分は従来の項目で今回の文字起こしとは連動しませんが手入力し全項目の入力が完了するとマスターcsvに追記できます。(記入しないと空白)
その後、SQLite3でデータ追加したマスターcsvをDBに変換し、クエリ操作によりS/Nから過去修理履歴を検索する試験的なアプリを作ります。
過去のデータを累積した、35項目のファイルはmaster35.csv、8項目のファイルをmaster8.csvとして、次のDB試験に使用することにしました。
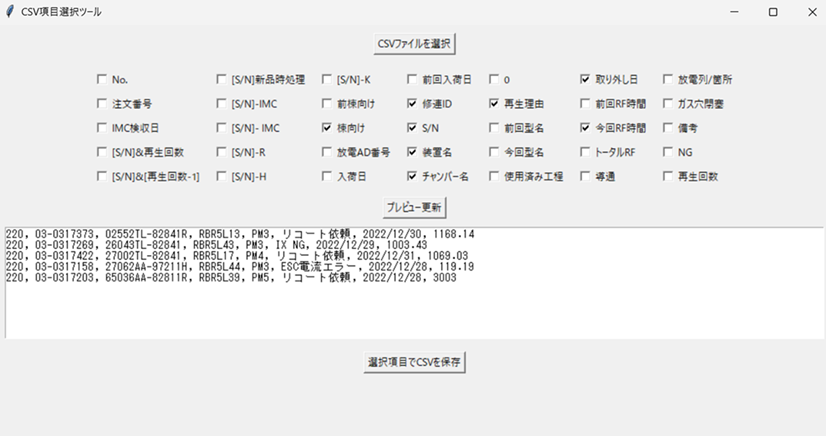
また、DBのチャプター管理を行うため、マスターCSVファイルから、伝票関係や部品処理関係といった項目に切り出すアプリも作りました。
マスターCSVファイルから、ユニークな修理IDを共通項目として用途別切り出しができるテストアプリの画面を示します。詳細説明は割愛します。今回は、VLM8項目を切り出したmaster8.csvをDB試験に使用しました。
前置きが長くなりましたが、LLMでクエリ操作を行う場合、SQLite3のDBを使用した方式が良いようです。そのためには、json形式やcsv形式をDBに変換する必要があります。修理連絡書から抽出した項目は、json形式で保存されますが、「IMC_CSV8」などのアプリでマスターCSVを再編集して追加保存する形式はcsvとしました。
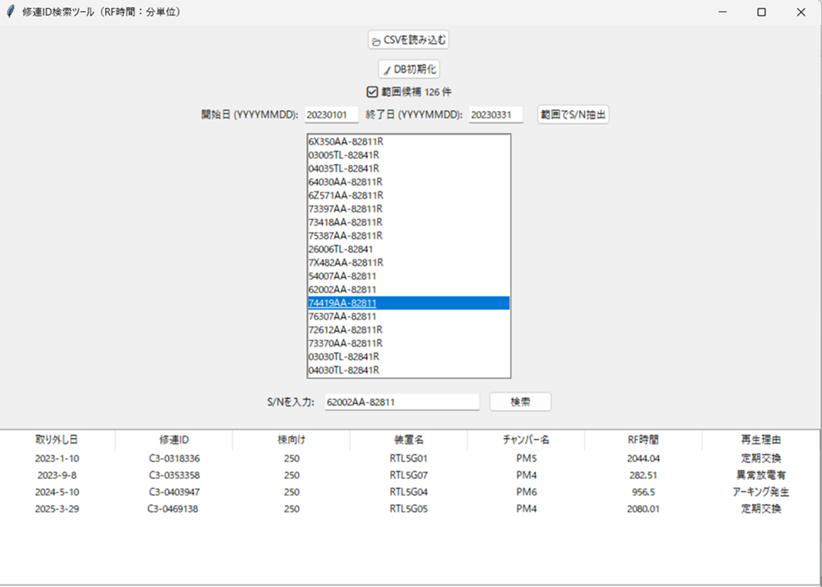
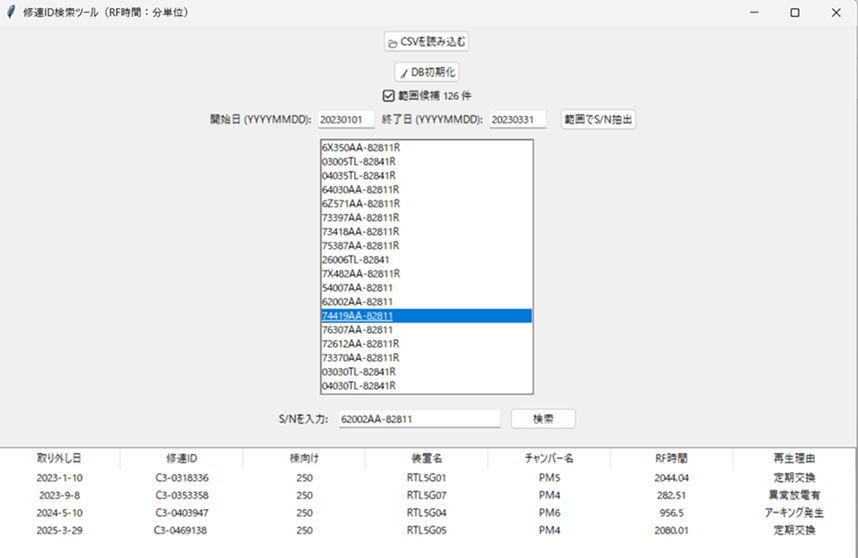
テストとして、S/Nを入力すると、S/Nに紐づく修連IDとその他項目を検索するアプリを開発します。
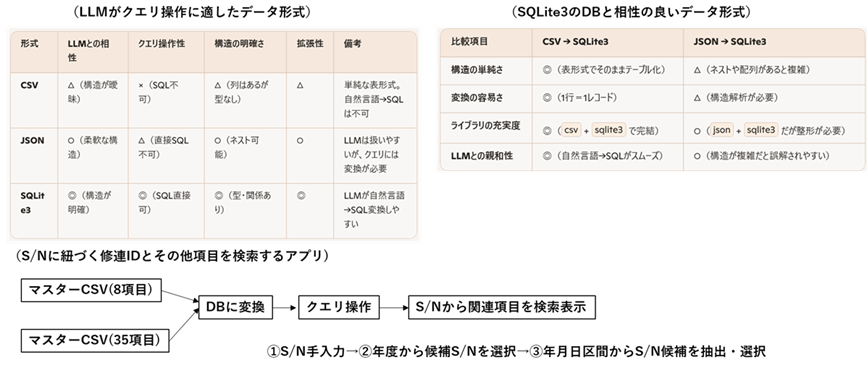
パーツを取り外した年月日の区間を設定し、その期間中のパーツシリアルナンバー(S/N)を一覧表で抽出し、クリックすることで、過去の修理IDほかの項目を検索し表示するテストアプリです。このパーツは過去4回修理に出されています。装置名と装着されたチャンバー番号と故障までの放電時間や故障理由がわかります。
修理履歴検索のテストアプリコードを示します。

コードの続きを示します。
最終目標は、このクエリ操作をpythonのSQLite3ライブラリをいちいち駆使するのではなくではなく、もっと柔軟にLLMがSQLite3にユーザーから言われたことを翻訳してテキストで指示することです。

