その1 構造データに対してのLLMの限界
ローカルでもLLMやVLMの性能が上がってきています。Copilotによるとcsv解析に適したLLMとして、「Mixtrail:8x7b」と「DeepSeekV2」があるようです。Mixtrail8x7bの量子化版は動かせますが、モデルサイズは26GBです。DeepSeekそのものはollama対応版がないため、「DeepSeek-Coder」を試すことにしました。

CSVデータの演算や元ファイルへの追加書き込みについて、できるものなのかを調べてみました。「test.csv」はX1~X4の説明変数と目的関数Yの数値を入れた構造です。まず、Yの平均値を求める電卓ののような処理を指示してみました。Mixtrail:8x7bは平均値と標準偏差を計算しましたが、deepseek-corder:6.7bは計算できませんでした。
無理は承知で、Yの感度解析を指示しましが、できませんでした。

「Mixtrail:7x8b」は、csvデータの演算が出来そうなことが判ったので、別な目的関数Y2=X2+X3+X4を定義し計算結果を出力するように指示しましたができませんでした。また「test.csv」ファイルへの追加書き込みもできないようです。現時点の生成AI(LLM)単体では、CSVデータを読み込んで「内部で実際に数値計算を行い、回帰モデルを訓練・推論する」ような便利なことはできません。

まとめると、LLMは「言語モデル」であり「数値計算エンジン」ではありません。
また、LLMは状態を保持できないため、CSVファイルを読み込んでモデルを訓練し、モデルを保持して推論するという状態管理ができません。「モデルを訓練して保存し、あとで使う」といった一連の処理は、外部の実行環境(Pythonなど)で行う必要があります。また、エクセルのような表計算ツールを扱えるLLMもないようです。クエリ処理などのDB検索などが得意なモデルはあるようです。そう考えるとエクセルなどの表計算ソフトは素晴らしいです。数値データの処理を行ってグラフに表示したり、アンケート調査など項目を検索して統計量を円グラフなんかにまとめることが簡単にできるツールですから素晴らしい。なのでエクセルを言葉で制御できる専用のLLMアプリがあれば欲しいのですが,,,,今回は、機械学習で回帰モデルを生成し推論する一連の操作の中にLLMを登場させて、モデル精度についてのコメントや学習データについてアドバイスを行うというハイブリッド型アプリ(なんちゃってAIアプリ)を開発したいと思いました。
まず、LangChainライブラリによるpythonデータ処理とLLMの協調のテストを行います。下図のように、一連のデータ処理をtool化(python関数)しLangChainAgentが見かけ上、AI処理の言語処理とデータ処理をシームレスに連携します。

このなんちゃってAgentの使用用途は、実験データを説明変数(X)と目的関数(Y)としてcsvファイルにまとめ、どの説明変数(x)の感度が高いとか実験データを使ったモデルとしてどの程度の精度が得られたのかを判断するツールです。機械学習ではおなじみの回帰モデル生成ですが、モデルの良し悪しなどがわかりにくいという意見をよくいただくことがありましたので、AIに生成したモデルについてコメントをもらうことにしました。以下にテストコードを示します。regression()関数はload_csv()関数を使ってcvsを読み込みdfに変換したものを受け取りRandomForest回帰を行います。結果のRMSEとR2値を返します。この値からLLMが回帰モデルの精度についてコメントするという流れです。

LangChainAgentとLLM(mixtral:8x7b)による回帰モデル評価コメントを以下に示しました。R2=0.95で良いモデルができたとコメントしています。

より軽量なLLM(gemma3:12b)にも同じ内容で回帰モデル評価コメントをしてもらいました。Pythonでデータ処理した結果をコメントするだけなら、Mixtrail:8x7bのような特別なLLMは必要ないことが判りました。

csvに強いとされたdeepseek-coder:6.7bは予想に反してダメでした。解読能力低くエージェントへの指示内容を正確に解釈できなかったようです。

その2 機械学習(回帰)+LLMによるデータ解析アプリの開発
任意の学習データ(csv構造)に対してRandomForest回帰による機械学習モデルを生成し、モデルの精度やデータについてAIがコメントをします。また、任意の検証データを読み込み推論結果を出力するGUIアプリを開発することにしました。
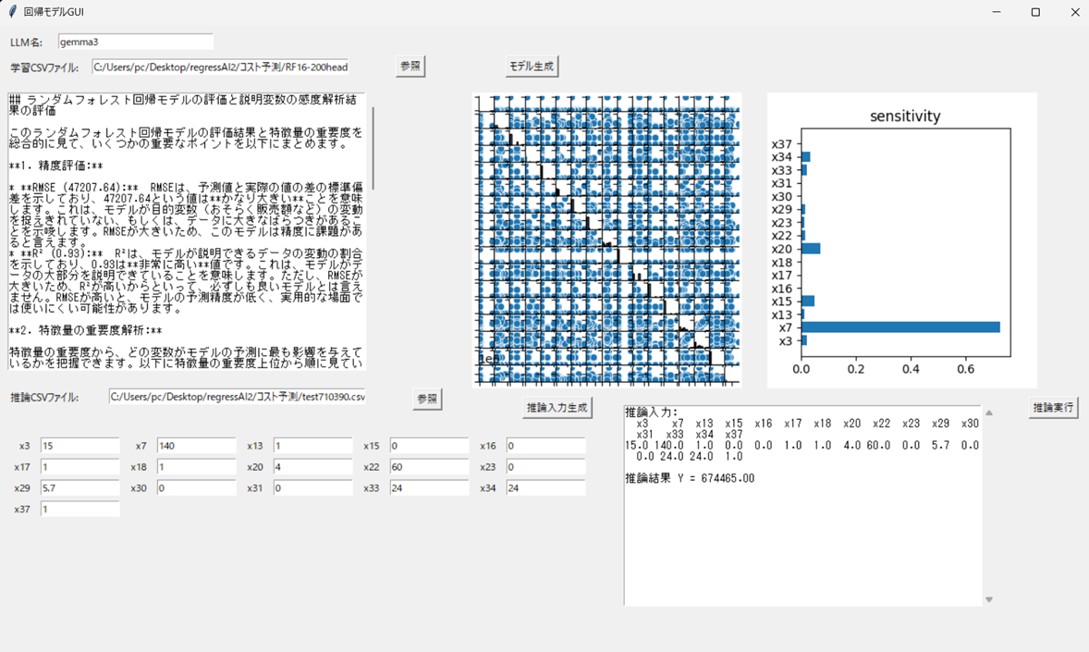
以下に開発したアプリ(regressAI)の操作画面を示します。Pythonプログラムで回帰モデルを作りAIがコメントします。LLMモデルは選択可、csvデータはヘッダに説明変数名と目的関数名(Yに固定)入れます。YについてRandomForestで回帰し回帰精度と感度分析結果をLLMに渡しコメントを出力します。PairPlotと感度解析結果グラフを表示します。推論は、学習用csvのヘッダーを共通にした1行だけデータを入れたものを使用します。読み込むと説明変数値がBOX表示されます。BOX内の数字は変更可能です。推論ボタンを押すと推論結果が出力されます。
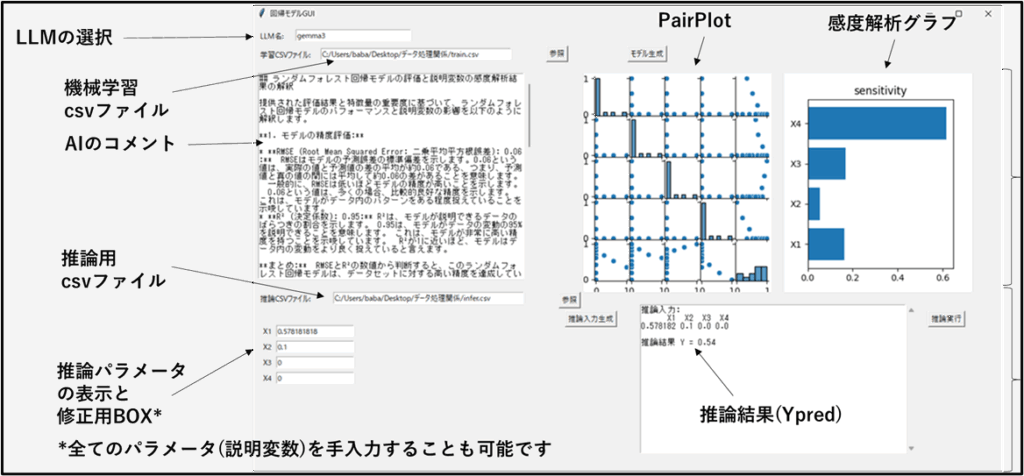
テストコードでは、AIにはRMSとR2だけを渡しましたが、追加で感度解析結果も加えました。regressAIのコードを示します。
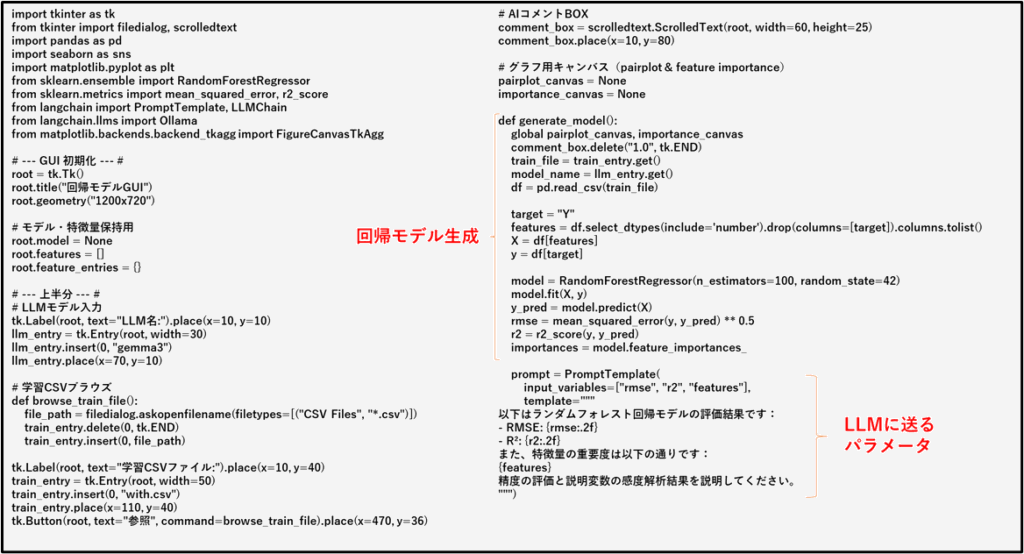

再度、学習推論アプリ(regressAI.exe)へのデータの与え方とGUIの操作方法を説明します。
学習データは、ヘッダーに説明変数(英文英数字で)とY(これはYに固定してください)を配置します。その下の行にデータ(数値)を入れた構造です。「参照ボタン」を押して、学習ファイル(.csv)を読み込み、「モデル生成ボタン」を押すと、回帰モデル生成~AIコメントの処理に入ります。少し時間がかかりますが、終了すると、AIのコメントとペアプロットと感度解析グラフが表示されます。説明変数数が多いと、ペアプロットは煩雑になりますが、対角成分の正規性(各説明変数の分布)や45度線に乗っかている相関グラフがあれば説明変数間の共線性をチェックできます。Yに対して各説明変数が正相関か負相関か無相関かを大雑把に把握できると思います。感度解析グラフは、回帰モデル(SVR/RandomForestを選択可能)RandomForestにすると各説明変数のYに対する感度が棒グラフで表示されます。説明変数の絞り込みに役立ちます。
GUIの下半分は推論用に作りました。推論データは、ヘッダーは学習データと同じものを使い推論したい説明変数だけを入れておきます。説明変数値は、入力BOX内に表示され編集が可能です。「推論実行ボタン」を押すと、説明変数値と推論値(Y)が表示されます。
繰り返して推論操作はできます。

その3 regressAIの応用例(価格予想)
装置容量に応じた電源装置をメーカーに発注する際に、見積価格が妥当かどうかの判断をしたい。過去の装置仕様と実績価格データを使って価格予測モデルを作ります。
回帰モデルの学習には、価格(Y)とそれに影響する説明変数(X1~X34の)34個、合計200組のデータを使用しましたが、今回は第一段の処理で説明変数を34→16個に減らしたところからスタートします。第1段の説明変数の削減は感度解析に基づいて行いました。
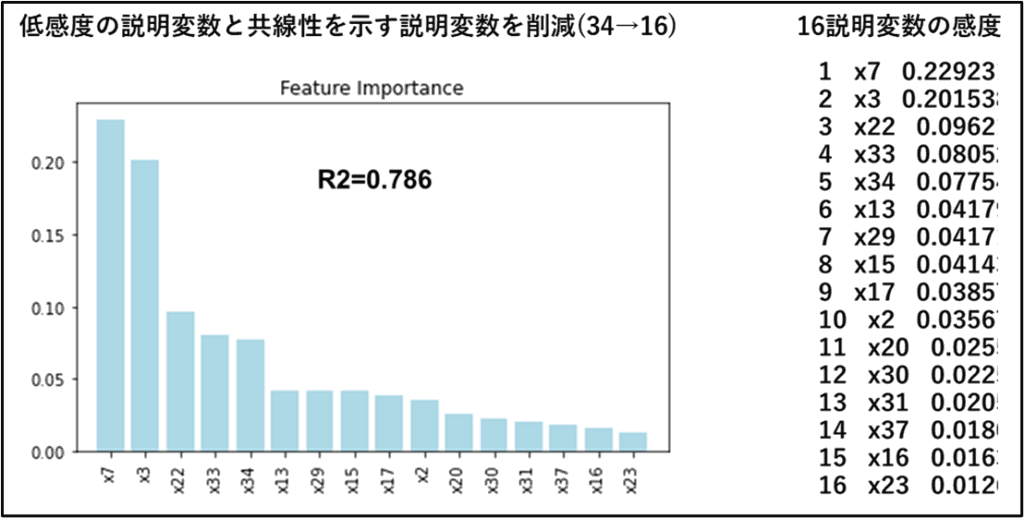
RandomForest回帰モデル生成と感度解析の基本コードを示します。LangChainでこの部分をtoolとして扱いエージェント化しますが、数値処理の心臓部分です。
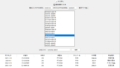
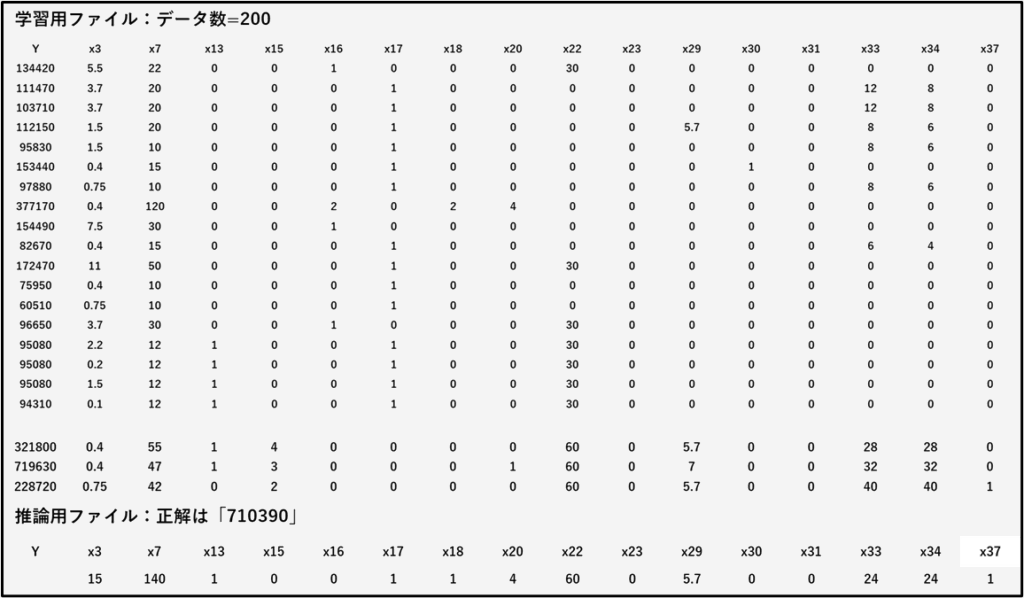
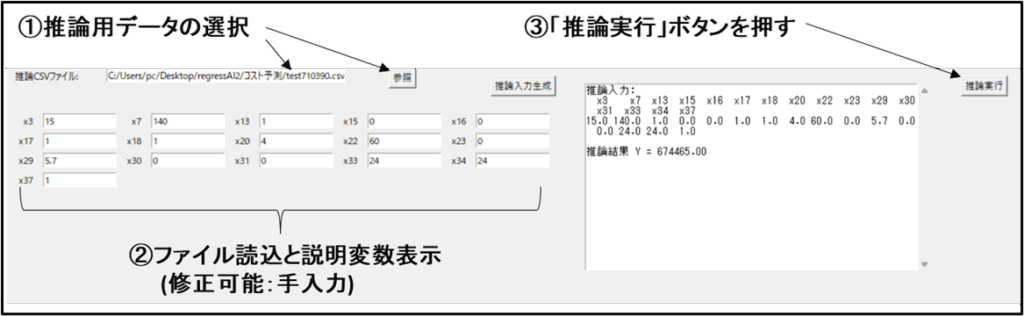
回帰モデル生成するための学習データと推論データを示します。学習データのYは実績価格です。推論データのYは空欄です。説明変数だけを使います。この推論データの実績値は「710390」でした。推論値がこの値とどれだけ違うか、後ほどGUIアプリで確認します。
以下に、「regressAI2」に学習データを読み込ませ回帰モデルを生成したのちに、推論用データを使って価格を予測するフルシーケンス終了後のGUI画面を示しました。予測価格は\674,465となり実績値(答)\710,930と比較して5%程度低めに予測しています。
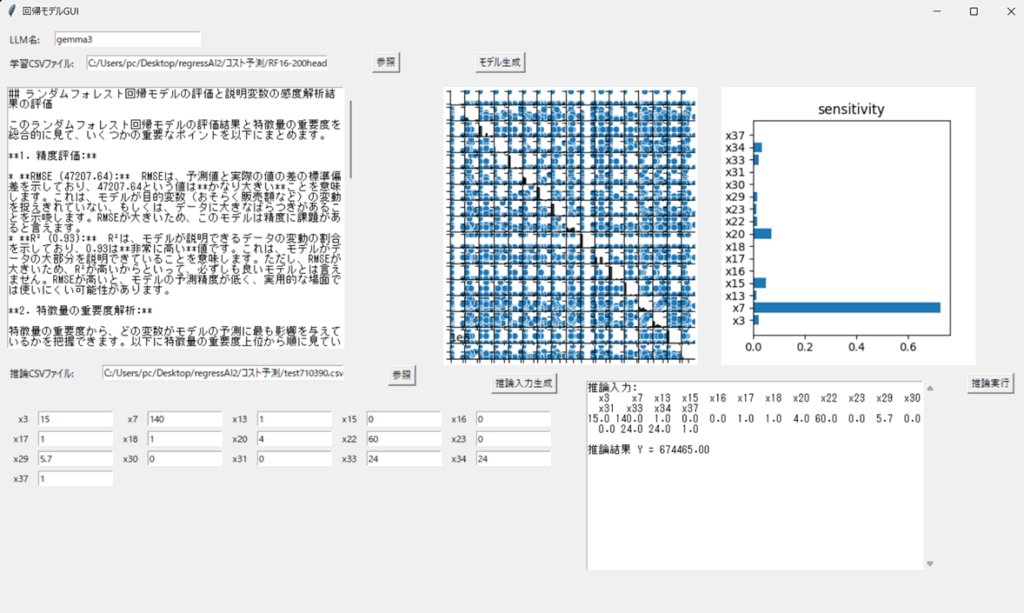
再度GUI操作とLLMのコメントを確認していきます。学習用csvファイル(ヘッダー付)を選択しモデル生成ボタンを押すと、pythonコードによる機械学習が始まります。機械学習は短時間ですが、LLMとのやり取りに時間がかかります。しばらく待つと、AIのコメント、PairPlot、感度解析グラフが表示されます。任意データによる推論はGUI下半分で処理します。

AIが回帰モデルについてコメントした内容全文を示します。モデルはRMSEがやや大きく改善の余地があることや感度解析に関するコメントも詳細です。データサイエンティストのような専門家に近い参考になる内容だと思います。

GUIの下半分は推論部分です。説明変数の調整が可能です。説明変数の数だけ入力編集BOXが表示されます。デフォルトで表示されているのは推論用に読み込んだデータ値です。任意の説明変数BOX値を書き換えて「推論実行」を繰り返すことで、パラメータの調整や感度解析などができます。
その4 regressAIの応用例(歯型占い)
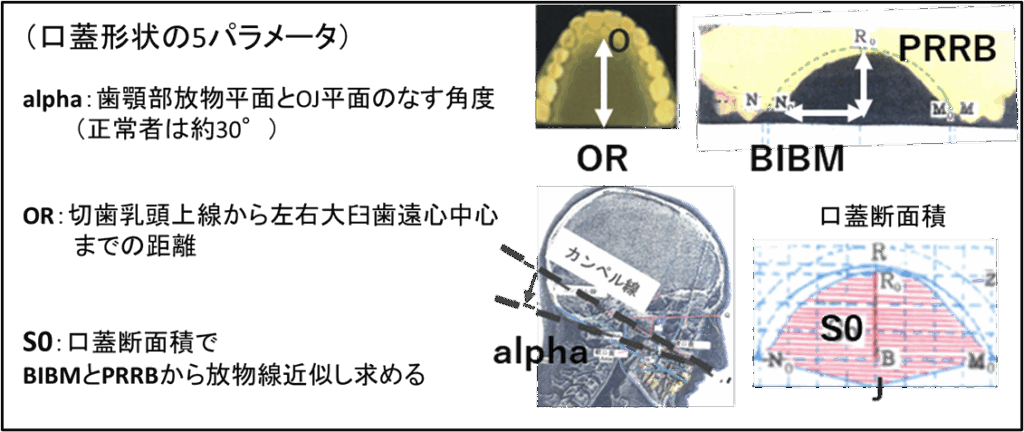
「口蓋形状から呼吸系・心臓系疾患を予測する手法の検討」というテーマで、第57回人工知能学会 AIチャレンジ研究会(2020年11月20日)で報告した時のデータを今回、開発したアプリ(regressAI2)に入力してみました。睡眠時閉塞性無呼吸症候群(OSAS: Obstructive Sleep Apnea Syndrome )と口蓋パラメータ(歯形)が密接な関係を持っているということを解析した内容です。口蓋形状から5つのパラメータ(X)を取り出し、OSASの問診指標(Y:0~7)を予測するモデルを作る健闘をしました。
機械学習に使った、5説明変数とYのデータ数の組は121人分です。以下に学習データの一部と学習データ以外の検証データを示します。(検証データの正解は5です。)

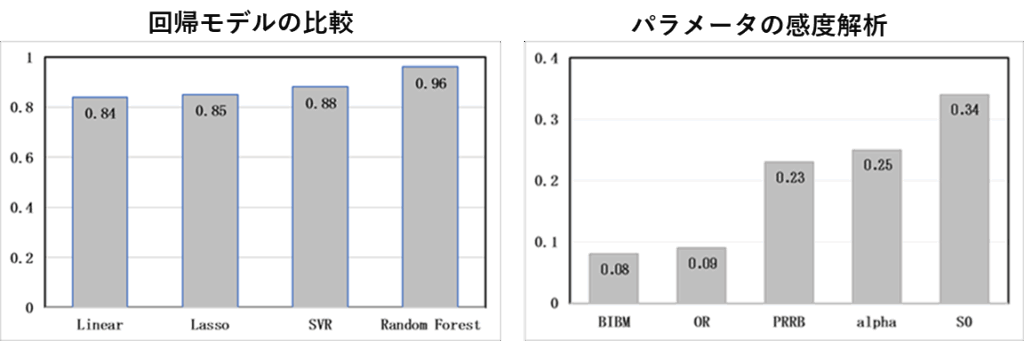
報告書では、回帰モデルとしてRandomForestが一番精度が良かったことと、感度解析では口蓋断面積(S0)の感度が高いことが判明しています。
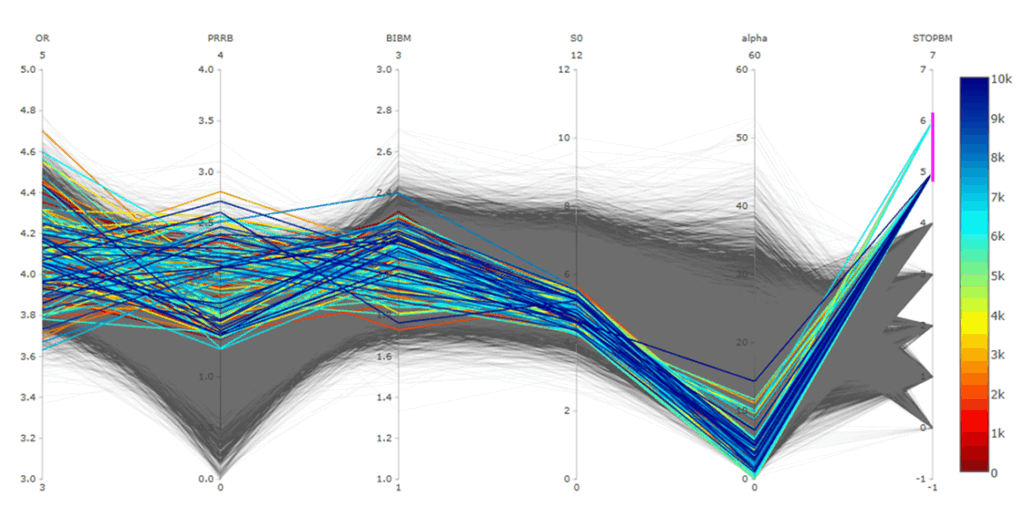
更に、各パラメータが正規分布をしていると仮定して平均値行列と共分散行列から、パラメータの組み合わせをランダムに10000組に増やし回帰モデルを使った予測値を動的平行線図で表現しています。右端のSTOPBANGは出力YでOSASの指標を表します。大きいほうが無呼吸症候群リスクがあります。S0とかalfaが小さい人はリスクが大きいようです。
regressAI2に2020年の同じ学習データ(hagata_train.csv)を読み込ませ、RandomForestで回帰モデルを作りました。一般的なデータ解析としてペアプロットと感度解析グラフが表示されました。感度解析ではalphaとS0です。報告書と順番が逆なのは、Random Forestのハイパーパラメータの設定が原因です。
推論データ(hagata_test5.csv)を読み込ませた場合の予測値は、4.22(正解は5)とよさそげな回答となっています。

生成した回帰モデルについてのコメントと感度解析結果をのコメントを示します。パラメータが何かをLLMに伝えていないため株価に関するパラメータと勝手に解釈している節がありますが、コメントとしては参考になります。カスタム化する場合はLLMへのプロンプトに、パラメータに関する情報を加えると、より専門的に答えてくれるかもしれません。