音声認識モデル(faster-whisper)の調査
1.faster-whisperとは
日経ソフトウェア2025年11月号(P36-P48)で、OpenAIが開発したオープンソースの音声認識モデル「Whisper」を高速化した派生モデルが「faster-whisper」で、GPUなしのそこそこのローカル環境でも動かすことができます。音声ファイルや動画ファイルから音声認識を行うため、ffmpegパッケージをインストールしておく必要があります。Windowsには標準搭載の音声入力機能があります。オフラインで動作しますが精度が低いことが問題でした。「faster-whisper」はローカルで高精度の音声認識が可能です。
日経ソフトウェア11月号の音声ファイルを文字変換する基本コード(P38 )を以下に掲載します。

faster-whisperのモデルはhttps://huggingface.co/Systran で提供されています。上記コードを実行すると初回は時間がかかりますがキャッシュフォルダにDLされます。2回目以降はキャッシュホルダの保存されたモデルを読み込みます。(例:“C:\Users\pc\.cache\huggingface\hub\models–Systran–faster-whisper-large-v3″)
アプリと同じカレントフォルダにmodelを配置することも可能なようですが、キャッシュフォルダと形式が異なるためコピーして持ってきても動きません。モデルには、「large-v3」のほかに「medium」「small」などが用意されていますが、速度は速くなりますが精度が落ちていきます。
速度については、「cpu」のほかに「cuda」の選択ができます。
RTX3060を使った場合、1/3程度の時間で諸織ができました。今回は、非力なノートPCで動かせるアプリをテーマにしています。「cpu」動作を前提にしようと思います。
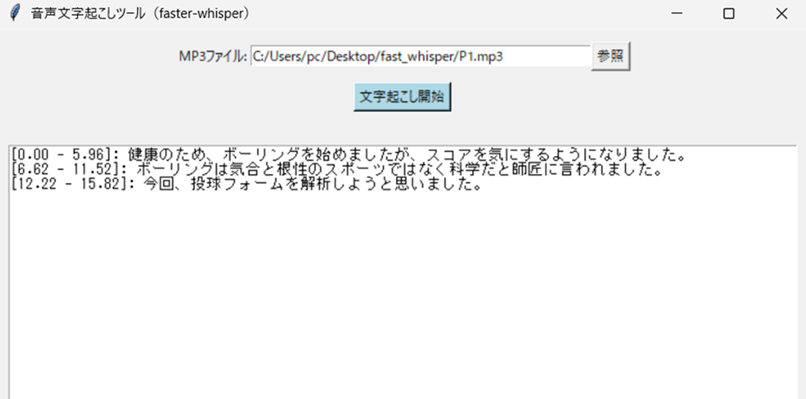
日経ソフトウェア記事を参考に、音声ファイル(mp3)の文字起こしGUIアプリ「mp3txtGUI.py」を作成しました。音声ファイルをブラウズ機能を使って選択し、「文字起こし開始」ボタンを押します。処理が完了するとGUIの出力BOXに、タイムスタンプとともに文字起こししたテキストが表示されます。「ファイル名.txt」に内容が保存されます。
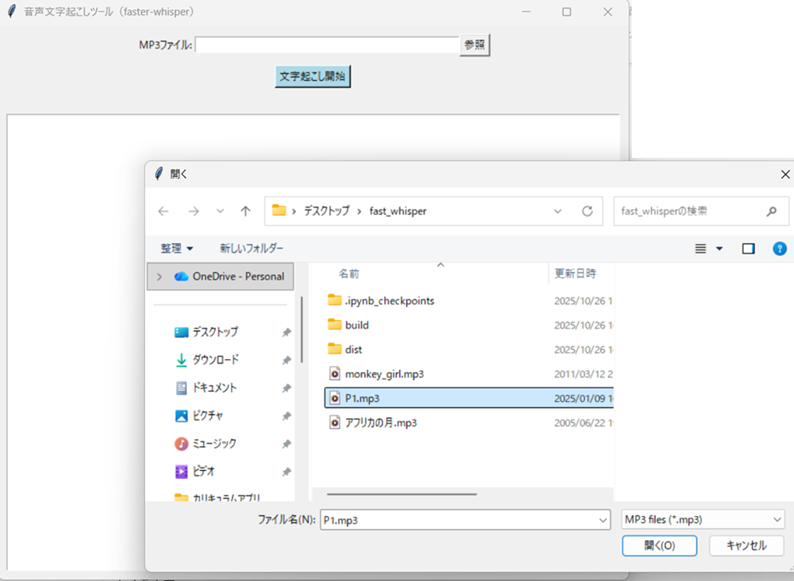
処理が終わるとテキストBOXに結果が表示されます。
「mp3txtGUI.py」のコードを示します。

文字起こしに使った音源は、OpenJ-Talkで合成した「ボウリングの科学」というプロモーション動画の女性ナレータによる冒頭の音声です。
Wordの文字起こしでは70%くらいの出来でしたが、faster-whisperはパーフェクトでした。従来AIと生成AIという対比では、生成AIのほうが優れていることが判りました。

Faster-whisperの精度が高いは判りましたが、音声ファイルからの文字起こしだけの機能では少し寂しいので、精度の高さを活かして、英語の同時翻訳機能を追加します。
2.英語翻訳機能の追加
文字起し次のステップとして音楽ファイルから歌詞の抽出と併せて歌詞の英文翻訳を行うアプリの開発を行いました。音声ファイル文字起こし(日本語と英語翻訳)GUIアプリ「mp3txtengGUI.py」です。
適当な音声ファイルがないので、メロディが含まれたバラード調の曲を聞かせてみました。
以下に、アンサリーさんが歌う「アフリカの月」という曲の変換を試みました。最初の2行は歌詞とは関係のない著作権的なことが出力されましたが、以降はすばらしい精度で歌詞を抽出しています。英語翻訳はオープンソースの「googletrans」ライブラリを使いました。
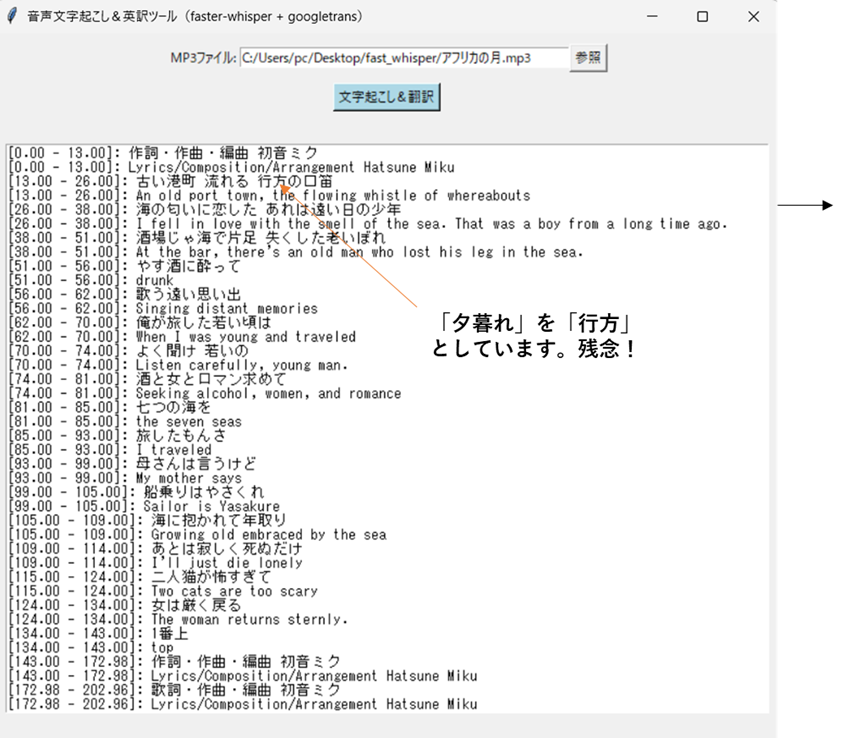
出力ファイルは日本語と英語で別々に生成します。
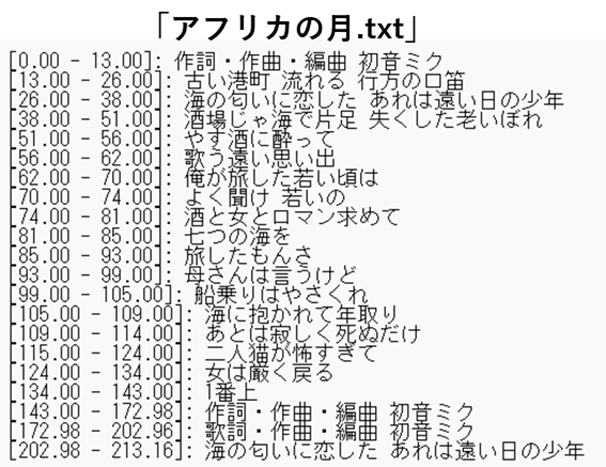
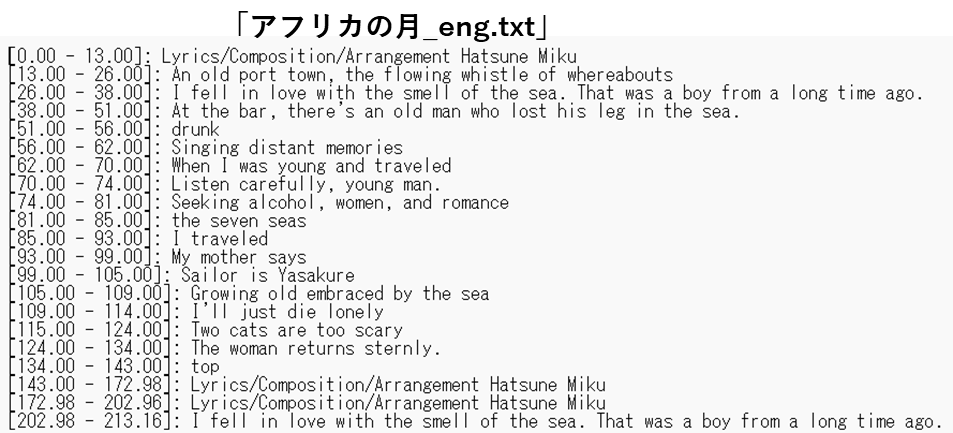
これは、結構便利なアプリかもしれません。この処理は、音声ファイルをベースにしているためオフライン処理です。処理は気長に待てば終わるので、ノートPCでも十分に処理ができます。次のステップはマイク入力による同時通訳です。処理にはGPUが必要です。
「mp3txtengGUI.py」のコードを示します。

3.マイク入力文字起こし
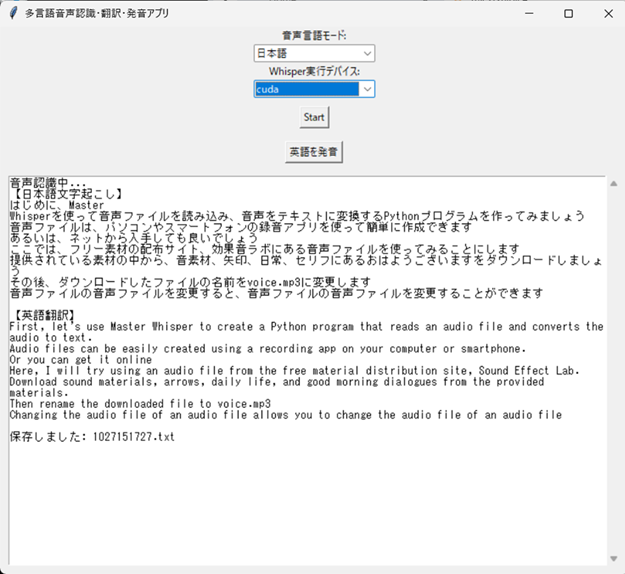
日経ソフトウェア2025年11月号(P41)に、マイク入力による文字起こしアプリの紹介がありました。基本動作を理解するには非常にありがたく、簡単にマイクで文字起こしできる優れものですが物足りません。日本語と英語テキストを同時出力する機能と英語翻訳したテキストを読み上げる機能を追加しました。また逆に英語音声を英語と日本語テキストに同時出力することもできます。(日本語の発音機能は割愛) 処理が重たくなることを想定して「cpu」と「cuda」の切り替えができるようにもしました。コミュニケーションツールとしても活用できるかもしれません。結果出力ファイルはMMDDHHSS.txtで保存されます。日本語入力例です。
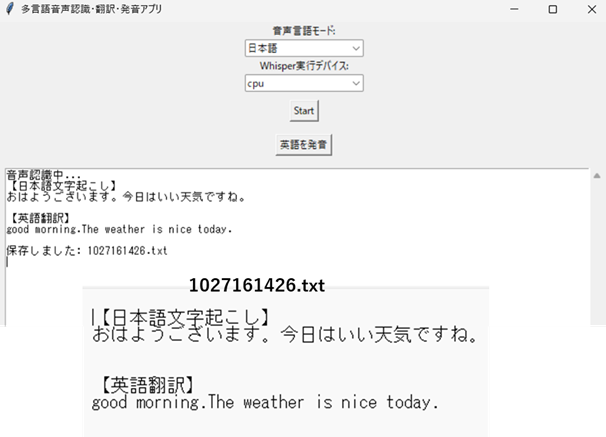
英語入力例を示します。
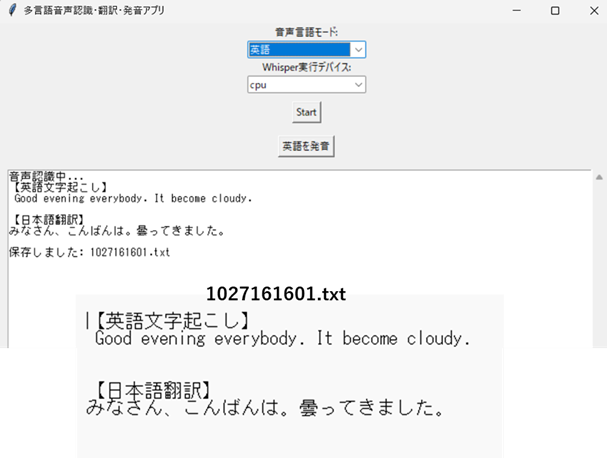
GPUによる処理(RTX3060)を行いました。cudaモードで、1分程度のマイク音声を変換してみました。変換にかかる時間は10秒程度でストレスを感じませんでした。日英同時翻訳はそこそこの精度ですが英語テキストの発音は、いま一つです。冠詞「a」をeiと発音しますしナチュラルではないような気がしました。

日本語と英語翻訳+発音GUIソースコードを示します。
「mictxtvoice.py」


4.動画ファイルの字幕合成
日経ソフトウェア2025年11月号(P44-P48)にfaster-whisperを使って動画ファイルの音声から、タイムスタンプを付加した文字起こしファイル.srtを生成するコード(リスト3)と.strファイルを使って元の動画ファイルに字幕を付加するコード(リスト4)が公開されています。追試しました。

元の動画に字幕を合成するコードです。

日経ソフトウェアの動画の字幕合成コードをベースにGUI化することと、英語翻訳字幕も生成できるようなアプリを開発しました。入力動画ファイル(.mp4)選択はブラウズ機能を持たせました。また、処理はcpu/cudaの選択ができます。字幕言語は日本語と英語に対応、字幕の位置(top/center/bottom)とサイズを選択できるようにしました。出力は、字幕付き動画(元ファイル_sub.mp4)と字幕テキスト(元ファイル_sub.txt)です。
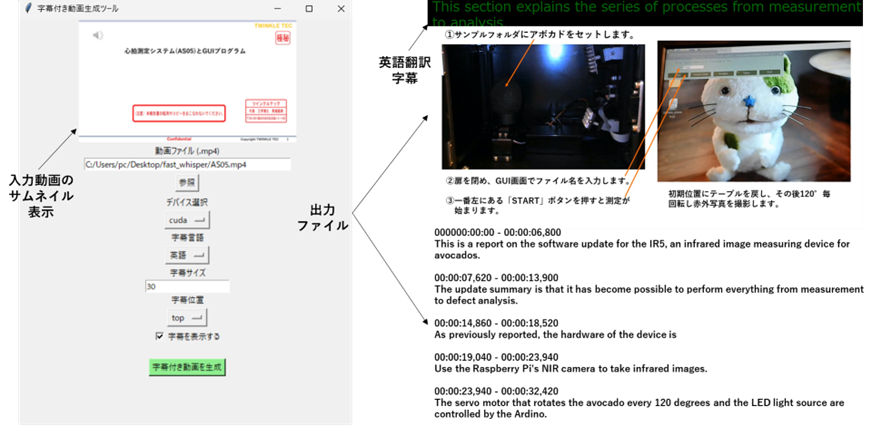
「movie_sub_transGUI.py」は、日本語の音声を英語に翻訳して字幕を合成するアプリです。音声は日本語ですが、表示は英語です。

「movie_sub_transGUI.py」コードの続きを示します。

プロモーションビデオにも字幕を付けてみました。下側に字幕表示すると収まり切れない場合があります。文字サイズも調整できますが、そもそも長い文章には向いていません。
5.画像生成AIの連携
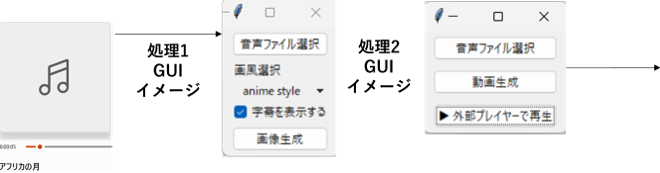
音声ファイルからの文字起こしには「faster-whisper」、抽出した文節を英文に変換して「stable-diffusion」で画像に変換します。2つの生成AIを経由したのちに字幕付き動画として出力します。何に使うのかは、例えば「歌詞付きの楽曲を入力するとカラオケ動画が自動的に作れる」といった応用を考えました。データ処理の流れを示します。

アプリの完成イメージを示します。



アプリのテストコードを示します。


最初は処理1と処理2を一体化してコードを検討しましたが、処理1が非常に重たく途中でKernelが停止するため、分離することにしました。中途半端ですが、今回はここまでとします。